A Quick Summary of "A Thorough Examination of the CNN/Daily Mail Reading Comprehension Task"
Teaching a machine how to read and comprehend has remained an elusive task in Natural Language Processing (NLP). The majority of information and knowledge that humanity has gathered thus far is stored in the form of plain text, and thus, the task of Reading Comprehension (RC) and Question Answering (QA) based on those text is a crucial component in not only NLP, but General Artificial Intelligence as a whole. Historically, large and realistic datasets have played a critical role for driving fields forward, such as ImageNet for object recognition. So when DeepMind researchers released the first large scale dataset for reading comprehension, it was certainly a historic moment. However, we may need to curb our enthusiasm - a more thorough analysis of their dataset, dubbed CNN/Daily Mail, reveals that: i) this dataset is easier than previously realized, ii) there exists significant noise in the dataset, and iii) current neural networks, like the one presented here, have essentially reached the performance ceiling on this dataset.
The Question Answering Task
DeepMind’s RC datasets are made by exploiting online news articles from CNN and Daily Mail, and their matching summaries. Let’s look at an example:

A single example is tuple of three elements: the passage p, the question q, and the answer a. The passage is the news article, and the question is formed in Cloze style, where a single entity in the bullet summaries is replaced with a placeholder (@placeholder). The replaced entity becomes the correct answer. The inference goal here is to predict the answer entity (Y) from all the appearing entities in the passage, given the passage and question (X).
As an important preprocessing step, the text is lowercased, tokenized, and named entity recognition and coreference resolution have been applied. This means that all entities are replaced with abstract entity markers (@entityn) according to the constructed coreference chain. The folks at DeepMind argue that such a process ensures that their models are understanding the given passage, as opposed to applying world knowledge or co-occurrence (and not “reading” the passage).
The two datasets are summarized in the following table:
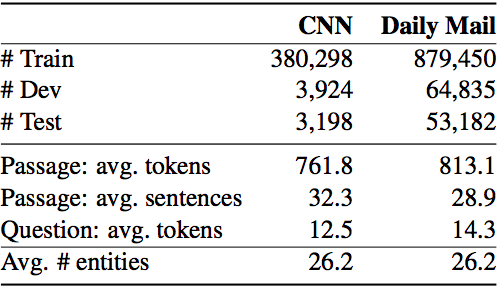
There are around 380k and 880k training examples (passage, question, answer) for the CNN and Daily Mail dataset, respectively. The average number of tokens, or words, for each passage and question is also shown. Finally, the average number of entities that appear in a single passage is also given.
The Two Models
In this section, two models are presented and evaluated to set a lower bound of the performance of current NLP systems. First, a conventional feature-based classifier is built by designing a feature vector f_p,q(e) for each candidate entity e, and learning a weight vector theta such that the correct answer a is ranked higher than all other candidate entities:
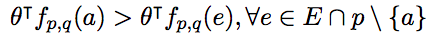
More interestingly, let’s examine a neural network model that is a modified version of the Attentive Reader model proposed by DeepMind. To make every step clearer, I have accompanied code snippets from my TensorFlow-based model here. The system can be described by the three following steps:
Encoding
Every token is mapped to a d-dimensional vector via an embedding matrix that was obtained from pretrained GloVe embeddings. For the passage, we use a shallow bidirectional recurrent neural network (RNN) using Gated Recurrent Unit (GRU) cells. A GRU cell performs similarly to a Long Short Term Memory (LSTM) cell but is computationally cheaper. The outputs from the forward and backward RNN are concatenated together to form the final passage encoding.
with tf.variable_scope('d_encoder'): # Encoding Step for Passage (d_ for document)
# Apply embeddings: [batch, max passage length in batch, GloVe Dim]
d_embed = tf.nn.embedding_lookup(embeddings, d_input)
d_cell_fw = rnn.GRUCell(args.hidden_size)
d_cell_bw = rnn.GRUCell(args.hidden_size)
d_outputs, _ = tf.nn.bidirectional_dynamic_rnn(d_cell_fw, d_cell_bw,
d_embed, dtype=tf.float32) # Create bidirectional rnn
d_output = tf.concat(d_outputs, axis=-1)
# [batch, len, h], len is the max passage length, and h is the hidden sizeWe do the exact same to encode the question, but instead of concatenating the hidden states for every single word, only the final outputs are concatenated.
with tf.variable_scope('q_encoder'): # Encoding Step for Question
# Apply Embeddings: batch, max passage length in batch, GloVe Dim]
q_embed = tf.nn.embedding_lookup(embeddings, q_input)
q_cell_fw = rnn.GRUCell(args.hidden_size)
q_cell_bw = rnn.GRUCell(args.hidden_size)
q_outputs, q_laststates = tf.nn.bidirectional_dynamic_rnn(q_cell_fw, q_cell_bw,
q_embed, dtype=tf.float32) # Create bidirectional rnn
q_output = tf.concat(q_laststates, axis=-1) # [batch, h]Attention
Here, we want to compare the question embedding and the passage embedding, and narrow down the entities that are relevant to the question.
with tf.variable_scope('bilinear'): # Bilinear Layer (Attention Step)
# M computes the similarity between each passage word and the entire question encoding
M = d_output * tf.expand_dims(tf.matmul(q_output, W_bilinear), axis=1) # [batch, h] -> [batch, 1, h]
# alpha represents the normalized weights representing how relevant the passage word is to the question
alpha = tf.nn.softmax(tf.reduce_sum(M, axis=2)) # [batch, len]
# this output contains the weighted combination of all contextual embeddings
bilinear_output = tf.reduce_sum(d_output * tf.expand_dims(alpha, axis=2), axis=1) # [batch, h]Prediction
Finally, the output from the previous step is fed into a dense layer and normalized with a softmax function.
with tf.variable_scope('dense'): # Prediction Step
# the final output has dimension [batch, entity#], giving the probabilities of an entity being the answer for examples
final_prob = tf.layers.dense(bilinear_output, units=args.num_labels,
activation=tf.nn.softmax, kernel_initializer=tf.random_uniform_initializer(minval=-0.01, maxval=0.01)) # [batch, entity#]Results
The final results are presented in the table below:
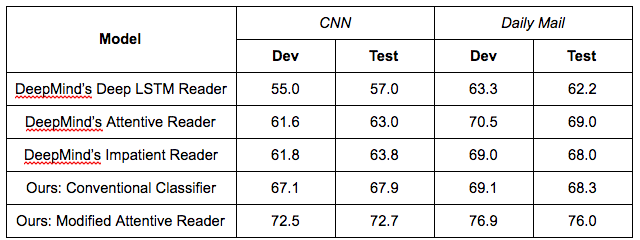
The conventional feature-based classifier obtains a 67.9% accuracy on the CNN test set, which actually outperforms the best neural network model from DeepMind. This implies that the learning task at hand might not be as difficult as suggested, as a simple feature set can cover many of the examples. In addition, our modified attentive reader surpasses the DeepMind’s previous results by a large margin (over 5%).
In-Depth Analysis
So now that we have achieved good results through both of our models, let us ask the following questions: i) Since the dataset was created synthetically, what proportion of questions are trivial to answer, and how many are noisy and not answerable? ii) What have these models learned? iii) What are the prospects of improving them? To answer these, we randomly sample 100 examples from the CNN dev dataset, to perform a breakdown of the examples.
After careful analysis, the 100 examples can be roughly classified into the following categories:
- Exact Match - The nearest words around the placeholder in the question also appear identically in the passage, in which case, the answer is self-evident.
- Sentence-level paraphrase - The question is a paraphrasing of exactly one sentence in the passage, and the answer can definitely be identified in the sentence.
- Partial Clue - No semantic match between the question and document sentences exist but the answer can be easily inferred through partial clues such as word and concept overlaps.
- Multiple sentences - Multiple sentences in the passage must be examined to determine the answer.
- Coreference errors - This category refers to examples with critical coreference errors for the answer entity or other key entities in the question. Not answerable.
- Ambiguous / Very Hard - This category includes examples for which even humans cannot answer correctly (confidently). Not answerable.
The following table presents the distribution of these examples based on their respective categories:

As one can clearly see, the last two “not answerable” categories account for 25% of this sample, thus setting the barrier for training models with an accuracy match above 75%. Further, only two examples require examination of multiple sentences for inference, suggesting that there is a lower rate of challenging questions than DeepMind originally showcased. Thus, it is reasonable to assume that for most of the “answerable” cases, the inference is based upon identifying the most relevant sentence.
Consequently, we can further analyze the predictions of our two systems, based on the same 100 examples and categorization. The results are as follows:
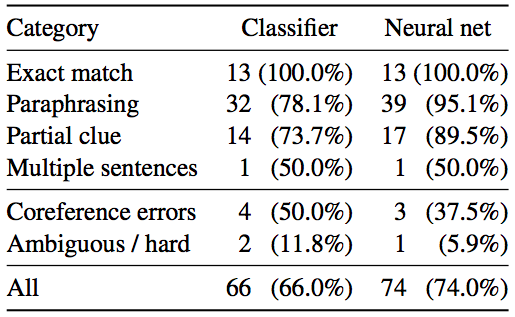
We can observe the following:
- The exact match cases are very simple to learn and both systems get 100% correct.
- Both systems perform poorly for the coreference errors and ambiguous/hard cases.
- The two systems mainly differ in paraphrasing and partial clue cases. This clearly demonstrates that neural networks are better capable of learning semantic matches involving paraphrasing or lexical variations between sentences.
- The neural net model seems to achieve near-optimal performance on all of the answerable cases.
Hence, due to the harsh upper bound on accuracy, set by the “not answerable” cases, it will be an unfruitful endeavor to explore more sophisticated NLP systems for this dataset.
Conclusion
Overall, this post was about the careful examination of the CNN/Daily Mail reading comprehension task. The two systems presented here demonstrates state-of-the-art results and an analysis by hand is carried out on a random sample of the CNN dataset. Even though the datasets are certainly valuable for their sheer size, it is evident that i) there exists significant noise due to the datasets’ method of data creation and coreference errors, ii) current neural network models have basically reached the performance ceiling iii) the reasoning required for inference is still quite simple.
< References >
Karl Moritz Hermann, Tomas Kocisky, Edward Grefenstette, Lasse Espeholt, Will Kay, Mustafa Suleyman, and Phil Blunsom. 2015. Teaching machines to read and comprehend. In Advances in Neural Information Processing Systems (NIPS), pages 1684–1692.
Danqi Chen, Jason Bolton, and Christopher D. Manning. A thorough examination of the cnn/dailymail reading comprehension task. In Association for Computational Linguistics (ACL), 2016.